

Bei Wired Space hat der Kollege Erfahrungen aus dem Entwicklerleben publiziert: diverse Probleme im Umfeld von Software-Deployments. Die gefundenen Schwierigkeiten waren:
- “But it ran fine on my machine.”
- “Manual deployment steps are prone to errors.“
- Kommunikationsschwierigkeiten im Team
Dabei ist letzterer Punkt, der immer wieder zu Problemen führt, noch nicht breit ausgeführt – aber das kommt wohl noch. Nichts desto trotz sind Deployments an sich schon komplex genug, sodass man sich auch alleine darüber schon lange genug auslassen kann.
Übersicht Deploymentprozess
Um die Probleme besser verstehen zu können, vorab eine kurze Beschreibung, was alles zum Thema Deployment gehört. Allgemein spricht man von Deployment, wenn eine Software(-komponente) auf eine Umgebung ausgeliefert wird. Das kann sowohl eine Anwendung/Applikation sein, als auch serverseitige Komponenten. Ferner kann es eine Voll- als auch Teilinstallation im Zuge von Aktualisierungen sein.
Neben dem reinen Aufspielen auf die Umgebung fallen ferner alle Prozessschritte darunter, die sich um die Anpassung der Komponente für die jeweilige Laufzeitumgebung beinhalten. Dazu gehören (ohne Erhebung auf Vollständigkeit):
- Einspielen von Konfigurationen in Datenbanken
- Kopieren von Konfigurationsdateien
- Migration von Konfigurationen
- Erstellung und Anbindung von Datenbanken und Queueing Architekturen
Teilweise handelt es sich um Schritte, die bei jeder erneuten Installation wieder durchgeführt werden müssen. Teilweise handelt es sich um einmalige Prozeduren (im Falle von Versionsaktualisierungen). Das ganze nochmal als Bild:

Doch nun zu den Problemen.
Problem 1 – “But it ran fine on my machine”
Das Team hat das Problem gehabt, dass die entwickelte Anwendung auf den jeweiligen Entwicklermaschinen sauber funktionierte, auf der Auslieferungsumgebung jedoch nicht. Es wurden folgende Beobachtungen gemacht:
- lokal installierte Bibliotheken sind nicht in die Entwicklung zurückgeflossen
- Es wurden teilweise „Debug Builds“ verwendet
Das klassische Phänomen dahinter ist, dass die Software nicht immer so gebaut wird, wie sie später verwendet bzw. ausgeliefert wird. Das ist an sich verständlich, da man für die Fehlersuche einen Debug-Build benötigt. Wenn jedoch nicht die korrekte Funktionsweise anhand eines „Delivery builds“ überprüft wird, ist die ganze Fehlersuche am Ende leider trotzdem für die Katz‘.
Aus diesem Grunde müssen immer zwei Konfigurationen berücksichtigt werden:
- “Debug builds” für die Fehlersuche während der Entwicklung
- “Delivery builds” für die Auslieferung
Dabei muß sichergestellt werden, dass Tests grundsätzlich immer gegen die “Delivery builds” stattfinden, also die Versionen, die tatsächlich beim Kunden eingesetzt werden sollen.
 Dabei ist das Verhalten bzw. die Testfälle zu protokollieren (im Falle von grafischen Anwendungen eignet sich dabei Wink sehr gut und ist zudem kostenfrei).
Dabei ist das Verhalten bzw. die Testfälle zu protokollieren (im Falle von grafischen Anwendungen eignet sich dabei Wink sehr gut und ist zudem kostenfrei).
Um das Problem zu umgehen, hat das Team auf Basis einer virtuellen Umgebung (VMWare, VirtualBox, Parallels Desktop, et cetera) eine Referenzumgebung aufgebaut, die immer wieder zurückgesetzt wurde.
![]() Die Virtualisierung bietet den Vorteil in einer definierten Umgebung arbeiten zu können. Dabei kann man sich die Umgebung so aufbauen, wie man es benötigt oder wie es beim Kunden im Einsatz ist. Mittlerweile beherrschen alle Systeme auch die Möglichkeit, Snapshots zu erzeugen. Damit wird der Zustand einer virtuellen Umgebung eingefroren und man kann zu einem vorherigen Zustand zurückkehren.
Die Virtualisierung bietet den Vorteil in einer definierten Umgebung arbeiten zu können. Dabei kann man sich die Umgebung so aufbauen, wie man es benötigt oder wie es beim Kunden im Einsatz ist. Mittlerweile beherrschen alle Systeme auch die Möglichkeit, Snapshots zu erzeugen. Damit wird der Zustand einer virtuellen Umgebung eingefroren und man kann zu einem vorherigen Zustand zurückkehren.
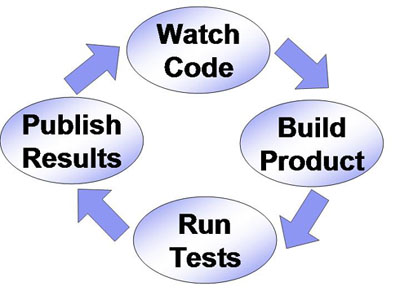 Neben der Virtualisierung bietet zudem das “Continuous Integration” eine gute Möglichkeit, Fehler sehr früh zu finden. Hierbei wird auf einer separaten Umgebung der bestehende Quellcode regelmäßig (im Idealfall: bei jeder Änderung) neu gebaut. Hierbei wird immer wieder frisch aufgesetzt, sodass fehlende Bibliotheken oder sonstige Änderungen unmittelbar auffallen.
Neben der Virtualisierung bietet zudem das “Continuous Integration” eine gute Möglichkeit, Fehler sehr früh zu finden. Hierbei wird auf einer separaten Umgebung der bestehende Quellcode regelmäßig (im Idealfall: bei jeder Änderung) neu gebaut. Hierbei wird immer wieder frisch aufgesetzt, sodass fehlende Bibliotheken oder sonstige Änderungen unmittelbar auffallen.
Problem 2 – Manual deployment steps are prone to errors
Hier liegt der Hase im Pfeffer bei der manuellen Durchführung. Normalerweise vergisst man manchmal Dinge im Eifer des Gefechts, oder es werden manuell noch „eben kurz“ Dinge nachgebessert. Dies führt dazu, dass jeder Installationsprozess „einzigartig“ ist und damit keine Wiederholbarkeit im Sinne einer Qualitätssicherung durchgeführt werden kann.
Um diesem Problem entgegen zu wirken, hat sich das Team dazu entschieden, Apache Ant einzusetzen.
Mit dem Tool können prinzipiell alle Schritte eines Installationsprozess automatisiert werden:
- Auspacken von Archiven
- Kopieren von Dateien
- Ausführen von SQL Skripten
Durch die Möglichkeit, Profile zu verwenden, kann man diese Skripte wiederum auf unterschiedlichen Umgebungen mit unterschiedlichen Konfigurationen ablaufen lassen.
Wie kann man aber anhand eines solchen Werkzeugs ein Verfahren entwickeln, mit dem sowohl Update- als auch Neuinstallationen geleistet werden können? Das Ziel eines jeden Prozesses ist es ja, für jeden Fall das gleiche Verfahren anzuwenden und nicht wieder von Fall zu Fall entscheiden zu müssen, wie eine Aktualisierung zu erfolgen hat. Nun, Ant bietet die Möglichkeit, anhand von Variablen bestimmte Verarbeitungsschritte zu überspringen. Ferner können ebenfalls externe Skripte eingebunden werden.
Variablen und “intelligente” Skripte für das “One Size Fits All” Verfahren
Hiermit ist es sehr elegant möglich, ein solches Verfahren zu realisieren. Für jede Installation wird das Installationsskript erweitert. Dabei werden diejenigen Teile, die für jede Installation notwendig sind, in allgemeine Sektionen (“Goals” im Ant-Jargon) zusammengefasst. Zudem werden nach dem allgemeinen Teil auch spezielle Sektionen durchgeführt, die jeweils nur für ein Versionsupdate gelten (1.0 –> 1.1, et cetera). Das Skript wird anschließend mit der installierten Version aufgerufen. Das Skript prüft dann bei jedem Spezialschritt geprüft, ob für den Schritt von der vorhandenen Installation zu der neuen Installation dieser Schritt notwendig ist und ggf. ausgeführt.
Das Ganze habe ich in folgender Grafik nochmal zusammengefasst:

Fazit
Man kann in relativ wenigen Spiegelstrichen zusammenfassen, was man aus den Erfahrungen lernen kann:
- Deploymentprozesse sind mehr als „Copy to directory“
- Manuelle „Fertigungstiefe“ muss reduziert werden, um Qualität zu erhöhen
- Wiederholbarkeit erhöht Sicherheit
- “Continuous Integration” unterstützt
- Virtualisierung ergänzt bestehende Infrastrukturen durch hohe Wiederholbarkeit und Verlässlichkeit der erzielbaren Ergebnisse
Gerade der erste Punkt sollte nicht außer Acht gelassen werden, denn es wird üblicherweise außer Acht gelassen, an was man alles denken muss 🙂
Eine Antwort auf „Software Deployments – Problemfälle der Softwareentwicklung“